Machine Learning for the Movies
(Note: This article originally appeared at
https://www.clarifai.com/blog/machine-learning-for-the-movies. If you are looking for a great computer
vision solution for your machine learning product, I highly recommend you
check out Clarifai!)
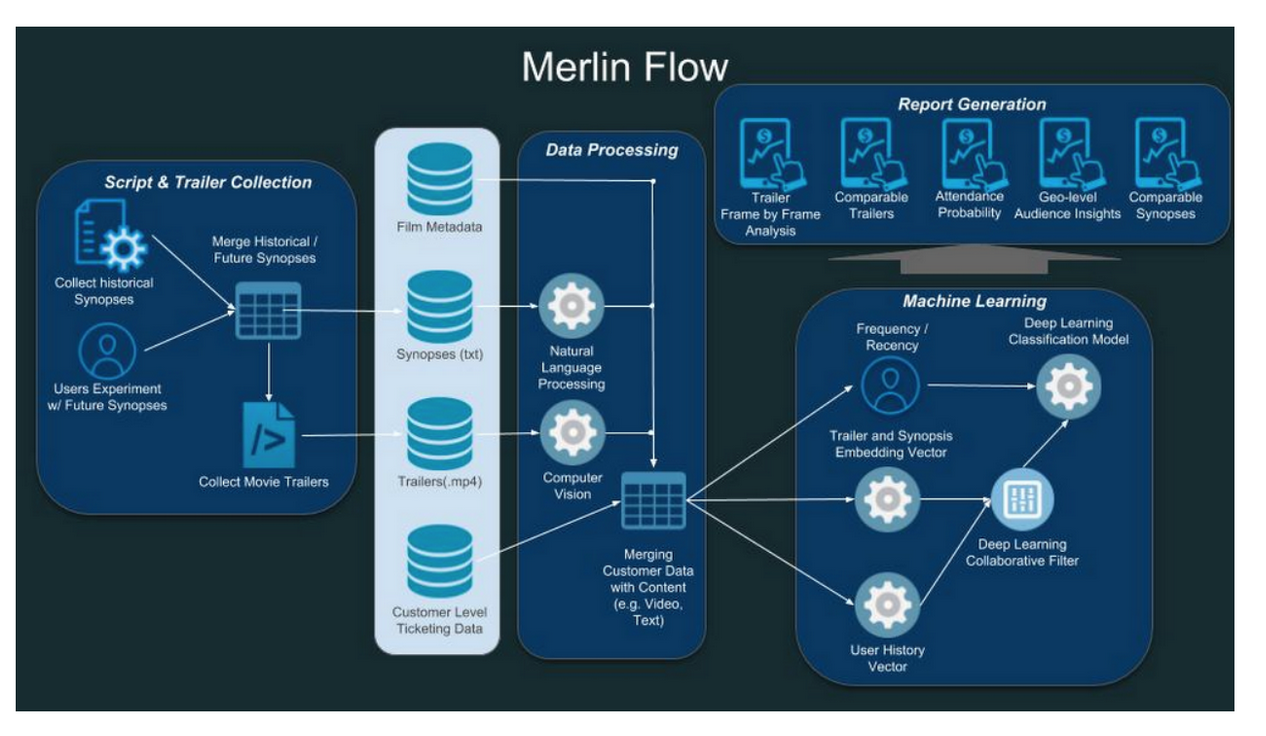
For many, machine learning is useful only insomuch that the insights it generates drive business or cut costs. Within the film industry, top studios have traditionally banked huge budgets on new scripts predicated on little but studio executives’ past experience, intuition, and hopeful conjecture. However, 20th Century Fox recently demonstrated that a paradigm shift within the entertainment industry may be underway. Their team of data scientists and researchers devised a machine learning model called Merlin Video that leverages film trailer data to predict which movies a filmgoer would be most likely to see given their viewing history and other demographic information. The team chose movie trailers as their object of study because they act as the most impactful determinant in a customer’s decision as to whether or not they will go to see a movie in theatres.
Understanding the Model Architecture
At the heart of Merlin are convolutional neural networks (CNNs), a type of model which has classically been used to achieve state of the art results on image recognition tasks. Merlin employs these neural networks by applying them to the individual frames of a movie trailer; however, the architecture includes clever processing steps which allow the model to capture certain aspects of the trailer’s timing. The model also relies heavily on a technique called collaborative filtering that’s commonly used when devising recommender systems. The crux of the idea is that a recommendation model should incorporate a wide diversity of data sources. In addition, it relies on the belief that if user A has similar tastes to user B on known data, then that shared similarity in preferences is likely to extend to unknown data.
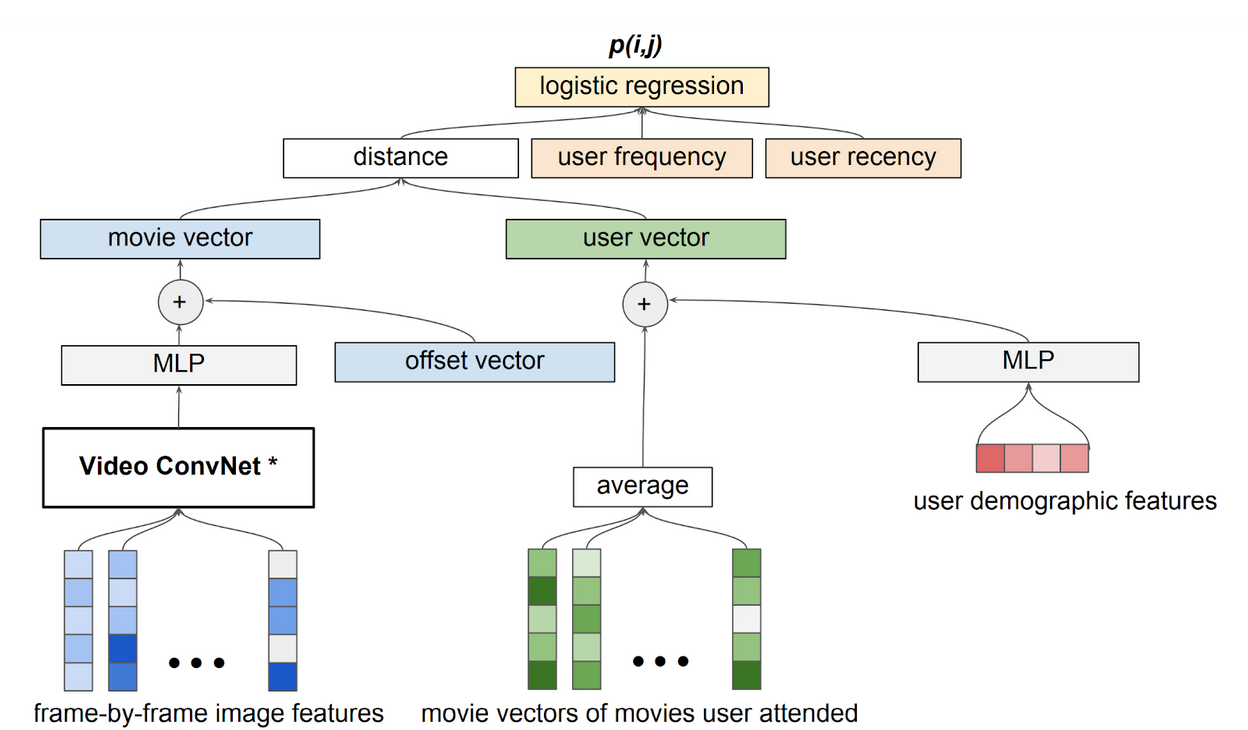
The output of the model relies primarily on what are called the movie and user vectors. The idea is that if accurate representations of each can be computed, then a proxy for the affinity a given user has for a given movie can be determined by computing the distance between their respective vectors. This distance is combined with user frequency and recency data and fed into a simple logistic regression classifier which provides the final output prediction giving the probability that user i will watch movie j.
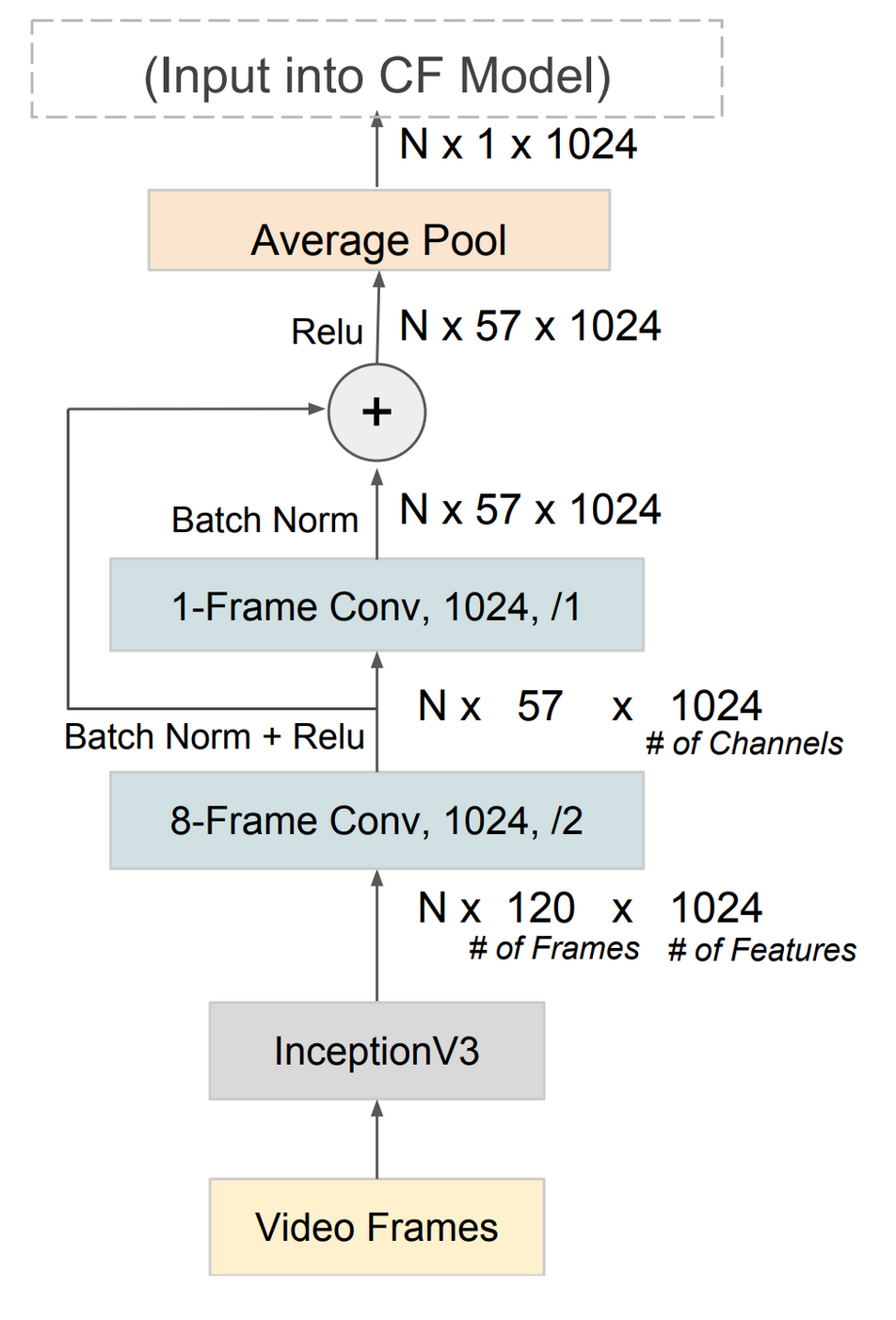
So how are the movie and user vectors created? The user vector is actually pretty simple. It’s just the averaged sum of the vectors corresponding to the movies that that particular user attended. As such, the real magic of the model relies in the creation of the movie vector. The movie vector is, in fact, created by the CNN previously alluded to. The global structure of the network is that it defines a number of features designed to capture specific actions relevant to a movie’s content. For example, one feature might seek to determine whether a trailer involves long, scenic shots of nature. This could indicate that the trailer is for a documentary. Another feature might try to detect a fast-paced fist fight indicative of an action movie. A key aspect of the model is that it goes beyond conventional CNNs by capturing the pacing and temporality of film sequences. That means it can tell the difference between quickly flickering frames which might indicate a flashback or a high speed chase and long, drawn out shots of dialogue or other slow-moving moments. Here’s the full diagram of the model which computes the movie vector.
Training the Model
The team at Fox trained the model on YouTube8M, a rich dataset provided by Google and consisting of 6.1 million YouTube videos annotated with any of 3800+ entities. The dataset provides 350,000 hours of video described by 2.6 billion precomputed audio and video features. This provides massive explanatory power for the Merlin model to take advantage of.
If you take a look at the above diagram which lays out the Merlin architecture’s data flow, you’ll see that they also feed the model film metadata, textual synopses, and data about the customer acquired at the ticket box.
Evaluating the Model
To assess the accuracy of their model, the team at Fox evaluated its predictions on the trailer of the recently released action flick, Logan. For those unfamiliar with the film, it’s an X-Men spinoff which focuses on the trials and travails of Wolverine as he wages war against the bad guys and saves the girl. Pretty typical Hollywood stuff. Astonishingly, the Merlin model captures the majority of the key ideas presented in the Logan trailer and uses these to accurately predict similar movies for filmgoers to see. Here’s the data that the Fox team got from the model and its comparison with actual customer behavior.
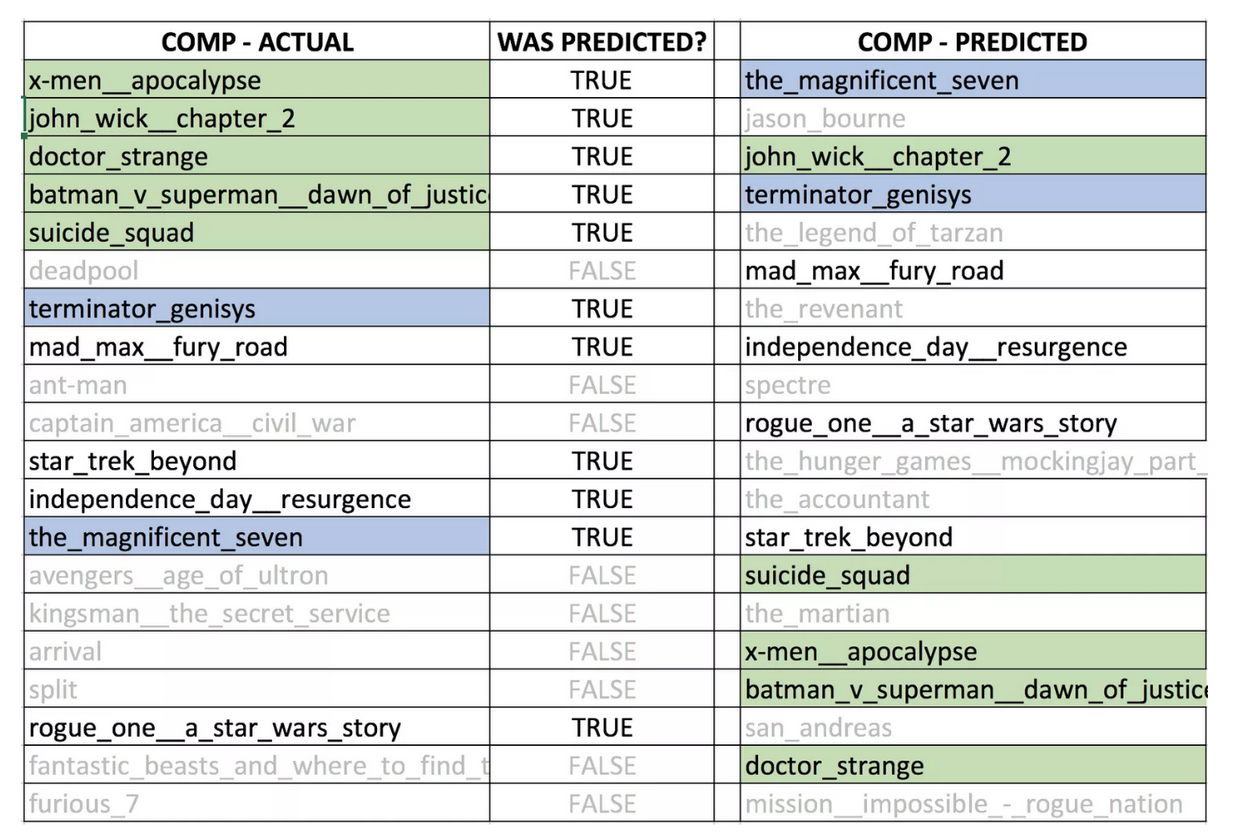
On the left, you can see the Top 20 movies that a user who saw Logan was mostly likely to watch. On the right, you can see the Top 20 predictions made by the model. Astonishingly, the model got all of the Top 5 actual movies within its Top 20 predictions. As a result, it’s reasonable to believe that the model was able to distill the key characteristics of Logan in order to infer its own predictions. That’s the power of machine learning.