Why Adding Epsilon Works
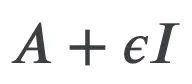
When people new to machine learning begin their journey, it is often stated to them (without proof) that a good way to ensure that a matrix $A$ is invertible is to add $\epsilon I$ to it, where $\epsilon$ is some small, positive constant. Of course, this simply amounts to adding $\epsilon$ along the diagonal of $A$. Making $A$ invertible without significantly changing its norm is necessary for the success of a variety of ML algorithms that rely on matrix inversion to obtain an optimal solution to some learning problem, as is the case in linear regression. This “epsilon trick” is often used unreservedly by practitioners, although often without an understanding of why it works. Here I give a proof of the validity of this technique using a theorem from differential geometry known as Sard’s Theorem. Here is the statement of Sard’s Theorem from John Lee’s book on smooth manifolds.
Sard’s Theorem Suppose $M$ and $N$ are smooth manifolds with or without boundary and $F : M \to N$ is a smooth map. Then the set of critical values of $F$ has measure zero in $N$.
To see how this theorem applies in our case, consider the determinant function, $\det : M_n(\mathbb{R}) \to \mathbb{R}$ where $M_n(\mathbb{R})$ is the space of real-valued $n \times n$ matrices. It’s an elementary fact that $M_n(\mathbb{R})$ and $\mathbb{R}$ are both smooth manifolds. Since $\det$ can be expressed as a polynomial function of a matrix’s entries, it is a $C^{\infty}$ smooth function. Now, we know a matrix is singular if and only if its determinant is zero, i.e. if $A$ is a critical value of the determinant function. If we let $X = \left\{A \in M_n(\mathbb{R}) : \det(A) = 0 \right\}$, then by Sard’s Theorem, $\mu(X) = 0$ so the complement of $X$, which is $GL_n(\mathbb{R})$, is dense in $M_n(\mathbb{R})$. Thus, setting $A \leftarrow A + \epsilon I$ will give a matrix $A \in GL_n(\mathbb{R})$ for almost every $\epsilon > 0$.
Daniel McNeela
Machine Learning Researcher and Engineer
My research interests include patent and IP law, geometric deep learning, and computational drug discovery.